
Text-to-speech (TTS) technology is changing the way we interact with our machines. It speaks to us from our smart speakers, virtual assistants, and voice bots. Combined with a range of smart technologies—automatic speech recognition (ASR), natural language understanding (NLU), dialog management, and natural language generation (NLG), at minimum—text to speech lets us issue commands and get responses entirely through speech. The resulting voice user interfaces turn computing into a more human experience.
But to really transform personal computers into personable computers, robotic TTS voices won’t do. Thankfully, artificial intelligence (AI) allows us to create synthetic speech that’s barely discernible from the real thing. This AI-powered TTS is called neural text to speech. It’s how the ReadSpeaker VoiceLab crafts custom synthetic voices for brands and creators. And thanks to AI, neural text to speech is more natural, expressive, and welcoming than ever.
If you’ve ever mistaken machine-generated speech for a human speaker, neural TTS is probably the reason why. Here’s what it is, what it can do, and why it’s important for your business.
📌 Key Takeaways
- → Neural TTS uses deep neural networks to generate speech from scratch — producing voices that are far more natural, expressive, and human-like than traditional concatenative methods.
- → Neural voices now account for nearly 68% of all TTS market revenue, and the technology is expanding into on-device, low-latency, and privacy-first deployments across education, gaming, transport, and customer service.
- → Brands can create custom neural voices they fully own — with emotional range, multilingual support, and deployment options from cloud APIs to fully embedded, offline systems.
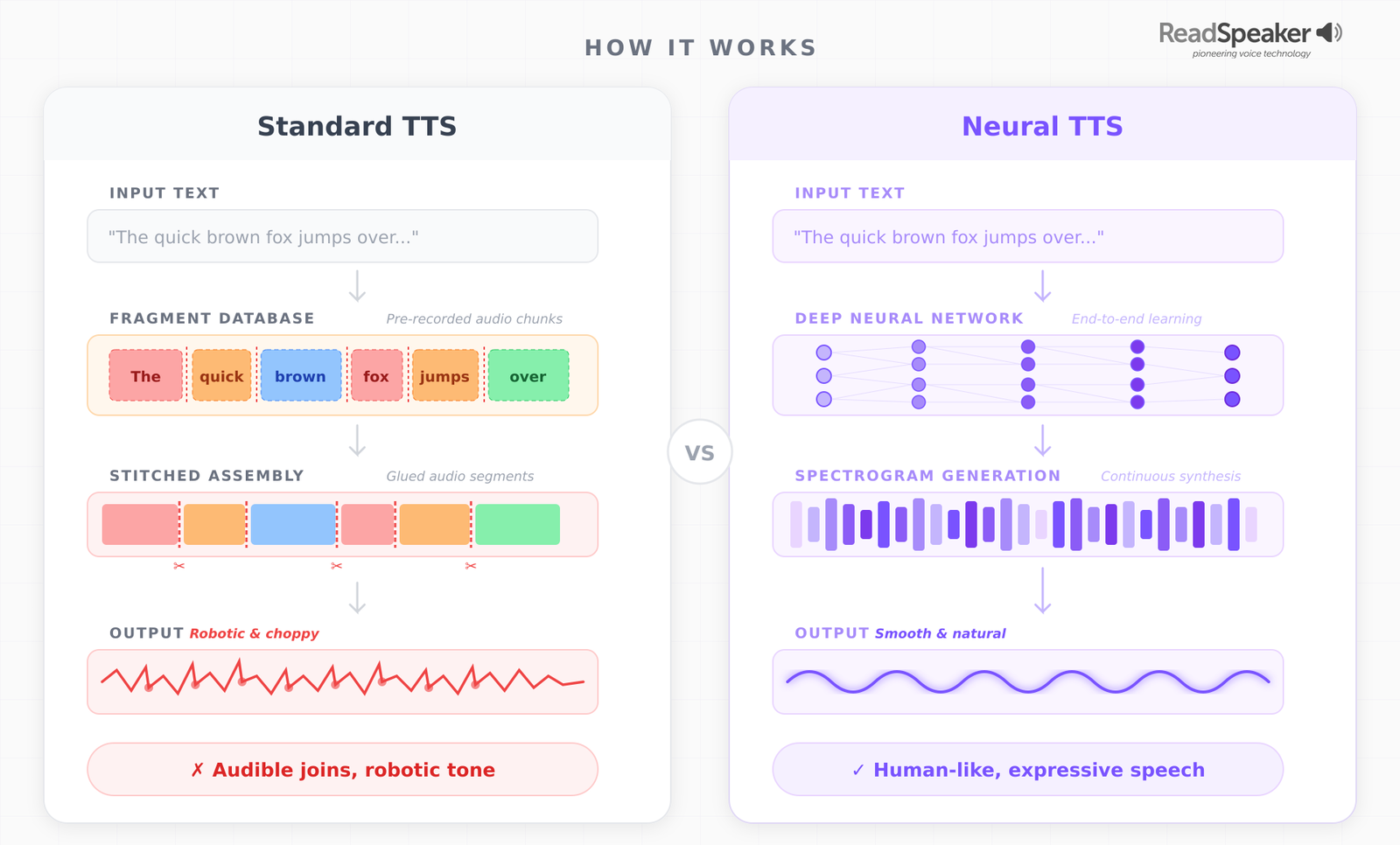
Hear the Difference: Standard vs. Neural TTS
Same text, two voices — listen to the difference
“Your order shipped this morning and arrives Friday. Want me to text you the tracking link?”
Voices generated with ReadSpeaker VoiceLab
Want to hear how lifelike neural text to speech can be?
Contact ReadSpeaker for a personalized demo
What Makes Text to Speech “Neural?”
In a nutshell, neural text to speech is a form of machine speech built with neural networks. A neural network is a type of computer architecture modeled on the human brain. Your brain processes data through unbelievably complex webs of electrochemical connections between nerve cells, or neurons. As these connective pathways develop through repetition, they require less effort to activate. We call that “learning.”
Neural networks loosely mimic this action. They’re clusters of processing units—artificial neurons—that classify input data and transmit it to other artificial neurons. By setting parameters for desired results, then processing large datasets, neural networks learn to map optimal paths from neuron to neuron, input to output. Unlike traditional computing, you don’t write the rules for a neural network; there’s no “If A, then B.” Rather, the network derives the rules from the training data. It’s a form of machine learning that’s been applied to everything from image recognition to picking winning stocks.
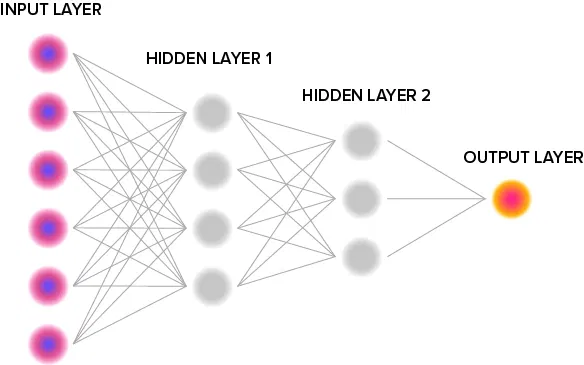
But not all neural networks are deep neural networks (DNN), the technology ReadSpeaker’s VoiceLab uses to produce more lifelike machine speech. We call a neural network “deep” when it consists of three or more processing layers:
The input layer initially classifies data, passing it through one or more “hidden” layers. These hidden layers further refine the signal, sorting it into more and more complex classifications. Finally, the output layer produces the final result: Labeling an image correctly, for instance, or predicting a stock fluctuation—or producing an audio signal that sounds uncannily like human speech.
Neural Text to Speech Models: Duration, Pitch, and Acoustic Predictions
To create a neural TTS voice, we train DNN models on recordings of human speech. The resulting synthetic voice will sound like the input data—the source speaker—which is why we often call neural TTS voice cloning. But it takes multiple DNNs working in concert to pull off this imitation act. In fact, neural TTS voices require at least three distinct DNN models, which combine to create the overall voice reproduction:
- The acoustic model reproduces the timbre of the speaker’s voice, the color or texture that listeners identify as belonging to that speaker.
- The pitch model predicts the range of tones in the speech—not just how high or low the TTS voice will be, but also the variance in tone from one phoneme to the next.
- The duration model predicts how long the voice should hold each phoneme. It helps the TTS engine pronounce the word “feet” rather than “fffeet,” for instance.
The pitch and duration prediction models are called prosodic parameters. That’s because they determine prosody, or non-phonetic properties of speech like intonation, rhythm, and breaks. Meanwhile, the acoustic model predicts acoustic parameters that capture information about the speaker’s voice timbre and the phonetic properties of speech. Today, we can combine these models for increasingly lifelike TTS voices with faster production times—and that’s just one of the capabilities DNNs bring to the field of machine speech.
New Possibilities for Neural Text to Speech Technology
The most obvious advantage of neural TTS is that it sounds better. In a 2016 study, participants rated DNN-based TTS systems as more natural than other types of TTS. A 2019 review of DNN-based TTS says that deep learning makes “the quality of the synthesized speech better than the traditional methods.” Since then, neural voice technology has continued to advance rapidly. According to industry analysis by Mordor Intelligence, neural and AI-powered voices now account for nearly 68% of all TTS market revenue—and they’re growing faster than any other voice type. But neural text to speech is also leading to unexpected TTS-production techniques that simultaneously reduce costs and improve quality.
That’s important for brands. Text to speech allows you to engage consumers through voice-first channels like smart speakers, virtual assistants, and interactive voice response (IVR) systems. Here are a few ways DNN-based TTS makes these experiences better for brands and consumers alike.
Prosody Transfer
Say you like the sound of one TTS voice but the speaking style of another. Prosody transfer makes it possible to get the best of both. As long as the two voices are compatible—meaning they’re in the same language, and they aren’t too far apart in pitch range—we can combine the prosody from one voice with the sound of another. For brands, prosody transfer makes it possible to give a custom branded TTS voice more expressive range—without starting from scratch for each new speaking style.
Speaker-Adapted Models
An advanced machine learning technique called transfer learning reduces the amount of training data required to produce a new neural TTS voice. Large datasets from existing TTS voices fill in the learning gaps left by shorter new voice recordings. While a few hours of voice recordings are always ideal for training voice models, speaker-adaptation allows us to emulate a new voice even when only shorter recordings are available. In other words, we can train these multi-voice models faster, with less original training data, and still produce lifelike TTS voices. This will help drive down costs and expand access to original, branded text-to-speech personas.
“Emotional” Speaking Styles
Training data determines the sound of every TTS voice. If you record three hours of someone speaking angrily, with large pitch variances and high intensity, you’ll end up with an “angry” TTS voice. With traditional text to speech, you needed a good 25 hours of recorded data to produce a decent voice—and that voice had to be relatively neutral in expression. With DNN models, you can get terrific results by training models on just a few hours of recorded speech—and even less with speaker adaptation.
These advances allow the ReadSpeaker VoiceLab to record three to five hours of a single speaking style or affective mood, then another hour or so of the same speaker performing in styles that suggest different moods. (Lacking these recordings, you could always find a more expressive TTS voice and use prosody transfer to mimic the performance.) That allows us to create voices with emotional variation, adjustable at the point of production through our proprietary voice-text markup language (VTML). So you can produce an enthusiastic TTS message, and another apologetic statement, all with the same, recognizable TTS voice, and all through the same TTS production engine.
Combine this capability with conversational AI to create automated chatbots, IVR systems, and virtual assistants that adjust speaking tone to match the mood of the speaker. That, in turn, improves the customer experience through fully automated voice channels. The conversational AI market is growing at over 23% annually, and as voice-first AI agents become the norm in customer service and marketing, neural TTS ensures these systems speak as naturally as they understand—building trust through voice quality that sounds genuinely human.
Where Neural TTS Is Heading: Trends Shaping the Future
Neural text to speech technology continues to evolve at a remarkable pace. The global TTS software market is projected to grow at over 16% annually through 2033, driven by AI adoption and multilingual demand. Here are the key developments transforming the field—and how ReadSpeaker is applying them for enterprise use cases.
On-Device and Edge TTS
Not every application can rely on a cloud connection. Train announcement systems, in-car navigation, gaming consoles, ATMs, and handheld devices all need TTS that runs locally—without latency, without an internet connection, and without sending data to external servers. Thanks to model optimization techniques, high-quality neural TTS now runs on embedded devices with small footprints, delivering natural speech in real time. ReadSpeaker’s speechEngine SDK powers neural voices in environments ranging from railway station announcements to game consoles—all running entirely on-device.
Ultra-Low Latency for Conversational AI
As conversational AI agents move from text-based chat to voice-first interactions, latency becomes critical. Users expect near-instant responses. Modern neural TTS engines can now stream speech output in under 200 milliseconds—fast enough to maintain the natural flow of a human conversation. This makes neural TTS an essential component of voice-powered customer service, virtual assistants, and interactive voice response (IVR) systems where every millisecond counts.
Multilingual and Cross-Lingual Neural Voices
Global brands need voices that work across languages and regions. Recent advances in neural TTS make it possible to create multilingual voices that switch seamlessly between languages while maintaining a consistent persona. ReadSpeaker offers neural TTS voices in over 50 languages and 200+ voices, with dedicated voices for regional accents and dialects—from American and British English to Arabic, Japanese, Hindi, and beyond.
Privacy-First Voice Technology
For industries like education, healthcare, defense, and finance, data privacy is non-negotiable. Neural TTS solutions that run on-premise or on-device ensure that no text data leaves the organization’s infrastructure. ReadSpeaker’s approach to ethical, privacy-first voice AI means zero data collection, full IP ownership for custom voice projects, and deployment options that keep sensitive information exactly where it belongs.
Interested in developing a neural text to speech voice to represent your brand across all your voice channels?
Contact us today to start the conversation
Frequently Asked Questions About Neural Text to Speech
AI-curious web developer at ReadSpeaker since 2014, I combine technical expertise with data analysis to drive innovation. Passionate about exploring new technologies, I’m motivated by complex challenges and always eager to push the limits of what’s possible. I explore the best AI tools and AI agents, helping professionals discover smarter ways of working.


